Code
import warnings
warnings.filterwarnings('ignore')import warnings
warnings.filterwarnings('ignore')Throughout this project, we addressed the problem of urban air pollution and whether it is related to racial and income demographics. We used multiple machine learning models, such as Logistic Regression, Decision Trees, Support Vector Machines, and others to see if it is possible to predict air quality based upon racial and income demographics from the U.S. Census. Our measure of air quality was the Environmental Protection Agency’s Air Quality Index. We determined feature importance to begin with, then determined which model was most accurate on the testing data. We found that it is possible to predict air quality with up to 93% accuracy on testing data based on racial and income demographics, but that many racial and income demographics were not stastically significant in determining the Air Quality Index. Our source code can be found here.
We aimed to address the possibility of disparities in urban air pollution based on racial and income demographics from the U.S. Census. This is an important problem to discuss and explore because in the case that disparities in urban air pollution are found based upon racial and income demographics, the solution could help determine where resources for decreasing air pollution should go. There have been a few studies that discuss this issue, including one by Environmental Health Perspectives, that quantifies exposure disparities by race/ethnicity and income in the contiguous United States for the six air pollutants that make up the total Air Quality Index (AQI) (Liu et al. 2021). In the study the researchers found that for each pollutant, the racial or ethnic group with the highest national average exposure was a racial or ethnic minority group. Another, from the American Lung Association discusses the impact of air pollution on premature death, finding that those who live in predominately Black communities are at greater risk of premature death from particle pollution (Association 2023). A study from the Harvard School of Public Health looked at how fine particulate air pollution, otherwise known as PM2.5, affects minority racial groups and low-income populations at higher levels than white populations and higher-income populations (Jbaily, Zhou, and Liu 2022). Another study by Columbia and published in the Environmental Health Perspectives journal also looked at PM2.5 and how nonlinear and linear models show the same direction of association between racial/ethnic demographics and PM2.5 levels (Daouda et al. 2022). A final study we looked at discussed how redlining maps drawn in the 1930s affect air pollution levels (NO2 levels) today, finding that redlining continues to shape systemic environmental exposure disparities in the U.S. today (Lane et al. 2022).
We are looking at slightly different information, looking at both linear and nonlinear models and how they relate to the AQI which takes into account the six air pollutants that the first study discusses, put together into a single index used by the Environmental Protection Agency (EPA). We are taking both racial/ethnic demographic information and income information into account. We are looking at urban air pollution specifically. We want to determine how urban demographics affect the AQI of certain areas to limit the scope of our experiment and see how far racial and ethnic demographics reach in their impact on air pollution. We hope that our research helps state, federal, and local governments determine how to allocate resources towards decreasing air pollution and increasing sustainable choices.
Potential users of our project include government officials, charity groups, lobbyists, citizens in highly polluted or non-polluted areas, or real estate investors. These groups would use our project in significantly different ways. When it comes to government officials, charity groups, and lobbyists, the hope is that decision-makers in power will view disparities in air pollution levels as problematic and worthy of attention. When they observe disparities based on racial or income demographics, hopefully it informs government officials and other decision-makers on where to allocate resources. Promoting sustainable energy, strict enforcement of the Clean AirAact, and other environmental practices in areas unfairly burdened with high air pollution could be a positive outcome of our project.
However, our project could also potentially cause harm. When thinking about real estate investments, poor air quality in lower income neighborhoods could provide more reason to avoid putting money into these areas. Families looking to move, buy, or rent in new neighborhoods may avoid neighborhoods that have poor air quality; if these neighborhoods are already low-income and mainly inhabited by racial and ethnic minorities, it will perpetuate systemic oppression that these communities already face. This could also be a reason for citizens inhabiting areas with better air quality – potentially more likely to be higher income, more white areas – to remain in their neighborhoods and continue investing in their own neighborhoods. This could perpetuate the differences in air quality between lower income and higher income neighborhoods.
Our personal reasons for working on the project include interest in the EPA data on air pollutants as well as a desire to see if bias plays into air pollution data in American urban centers. I personally began reading news articles and studies covering the effect of income and racial demographics on pollution starting in the middle of high school. Making our own datasets, models, and maps helped us grasp those disparities much more concretely and explore how far these disparities extend. Finally, there is a hope that our data helps understand whether disparities in air pollution, based on the Air Quality Index, exist dependent on racial/ethnic and class demographics. While it is not necessarily right that numbers, data, and statistics are often required to make policy decisions, it is the current way of life. Decision-makers can hopefully utilize projects like ours to make decisions that help allocate resources in a way that decreases disparities.
Based on this reflection, the world would hopefully be a more equitable, just, joyful, peaceful, and sustainable place based on our technology. With resources allocated towards neighborhoods unfairly suffering from poor air quality due to systemic racism and classism, the United States can hopefully take a step towards paying reparations for the historical and current oppression that has compounded on minority – and particularly low-income minority – groups.
For this project, we used 3 different data sets: - Air pollution data by county - Income data by county - Racial demographic data by county
Our first step in the process was data cleaning. We hoped to combine these three data sets into one larger dataset that included air pollution, income, and racial data for each county. We started with the pollution data and dropped any columns that were used for labeling units. (ie. NO2 units: ppm, 03 units, etc). These columns had the same value for all entries and add no additional value. We also dropped the values that are used to directly calculate the AQI, such as ‘NO2 Mean’, as these features would clearly have an impact on AQI beyond racial or income demographics. The environmental data was collected nearly everyday for many years, so we decided to find the average values for each year (per county). We iterated through all of the entries, keeping only the first four character of the date local column (the year). Then we grouped by state, county and date local to get the yearly averages for each county.
We determined a binary AQI label based upon suggestions from the Environmental Protection Agency (EPA). The EPA determines ‘good’ and ‘moderate’ air quality as any AQI from 0-100. Beyond that, any AQI above 100 is considered unhealthy for sensitive groups. That information can be found more in depth here. We labeled ‘good’ AQI as 1 and ‘bad’ AQI as 0.
Next, we incorperated the county income data. This data set only included the fips code, state abbreviation and median household income, so we could left join on fips code and state abbreviation to combine the two data sets.
The last step was to incorporate the racial demographic data. This data set had many columns, but to simplify it, we only considered the individual race columns. Again, we inner joined, to only included counties that appeard in both data sets.
No we have one data set with state, county, pollution, income and racial demographic data.
One of our first steps in methodology was determining feature importance of each of our features. When determining feature importance, or the effect feature has on the predictive power of the model, we used the built in feature importance of the Random Forest model. This feature importance is calculated by the Mean Decrease in Impurity, or the MDI. For each feature, the random forest algorithm calculates the average decrease in impurity across all decision trees while constructing them. In simple terms, it calculates each feature importance as the sum over the number of splits – in all decision trees – that include the future – proportionally to the number of samples that feature splits. Features which increase the purity of each split (or the likelihood that the particular split will lead towards an outcome of 1 or 0) are tagged as having higher feature importances.
The bar plots of feature importance can be found below:
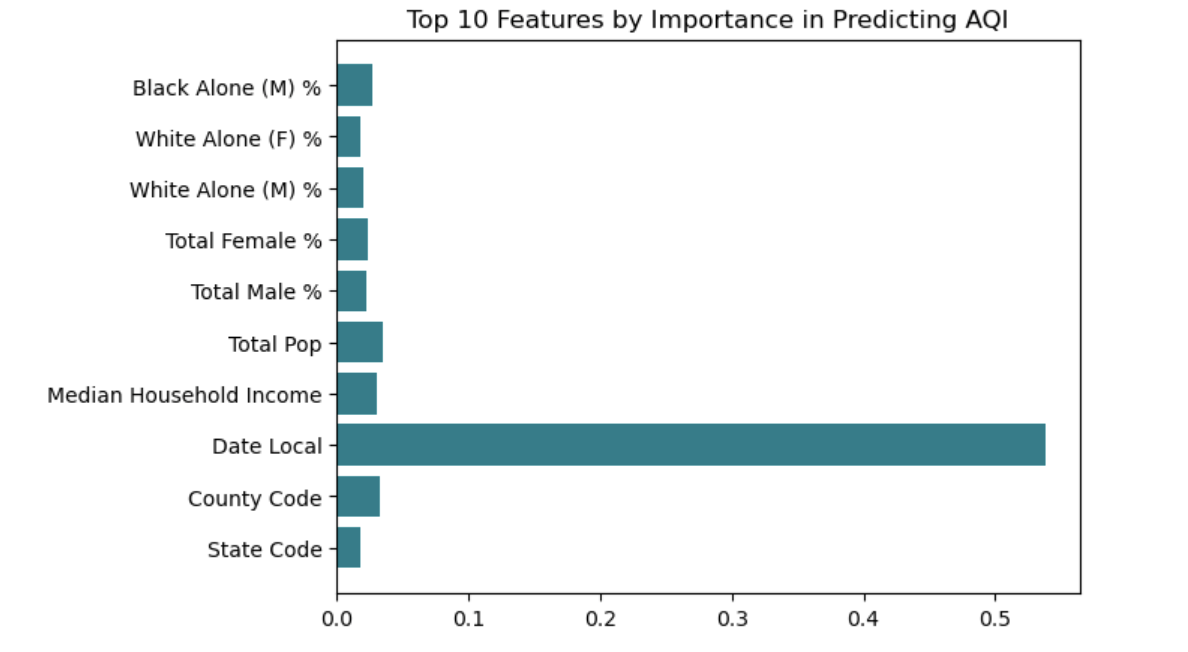
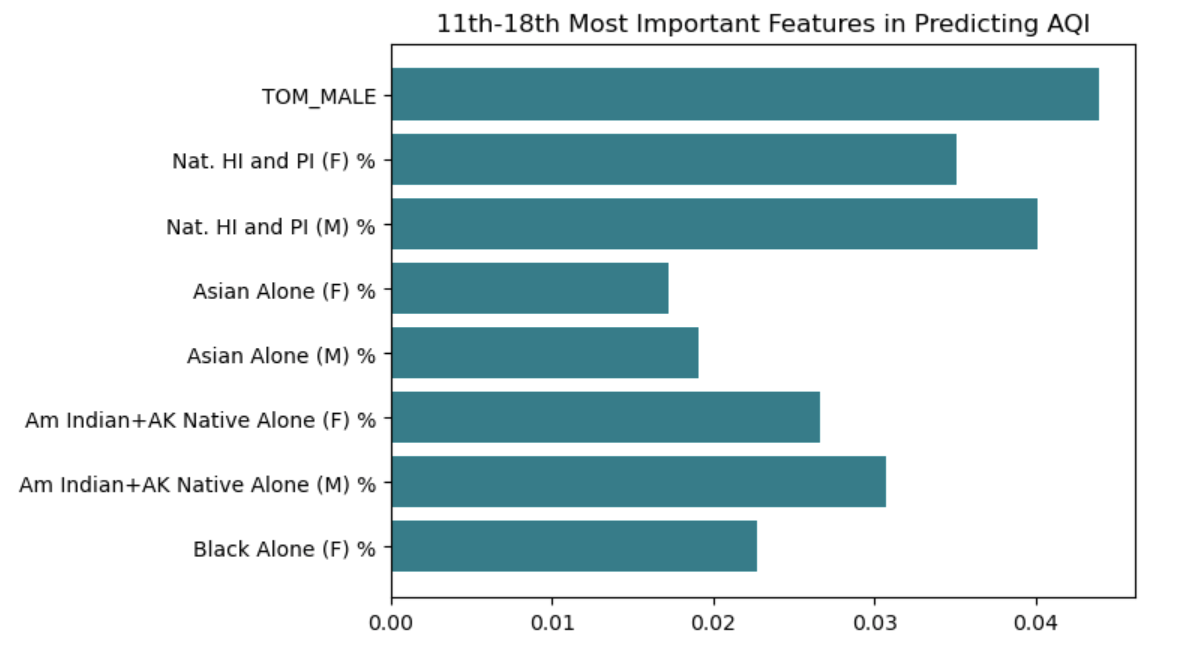
Something we noted when documenting feature importances was that all features had relatively low importances. Furthermore, some of the features with highest predictive power, like total population and date local, had little to do with racial and income demographics. We will discuss this more later in the results section.
We looked into a few different scikit models and compared the results in order to determine which models we wanted to use in final processes. When looking at models, we kept in mind that the base rate of our dataset is 86.05%. Any accuracies we determined from models should be higher than that base rate.
The logistic regression model resulted in a training accuracy of 89.2% and a testing accuracy of 86.05%. The testing accuracy was not higher than the base rate, meaning the logistic regression model was not anble to aid in predicting AQI outcomes.
We looked at the linear regression model in order test the statistical significance of our different feature variables. The training accuracy was 22.2% and the testing accuracy was 24.7%. We used a p-value of <0.05 a threshold to test for coefficient significance. The table of p-values can be found below.
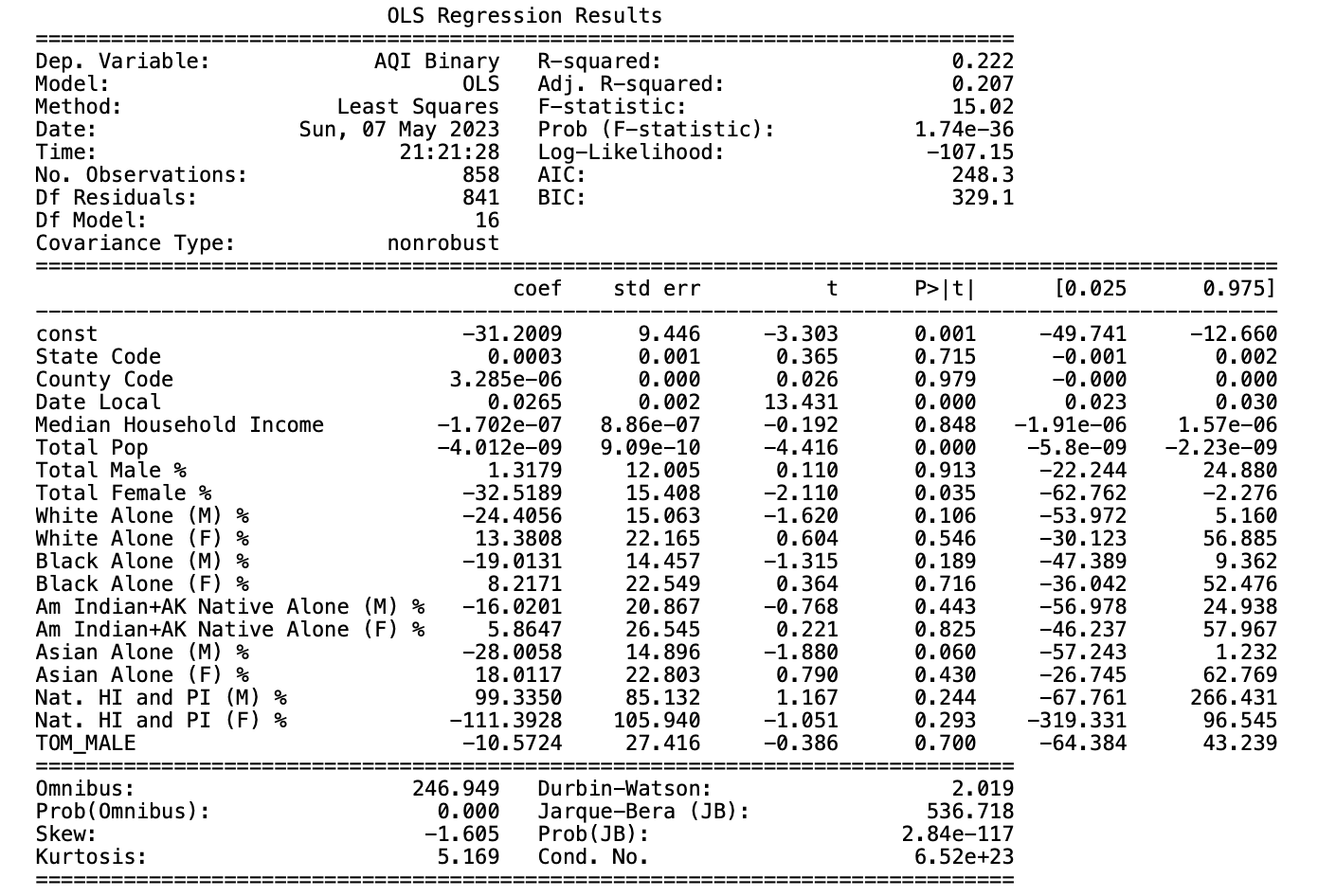
What this table shows is a few features carrying statistical significance in our model. The features that are statistically significant are Date Local, Total Population, and Total Female Percentage. One feature, Asian Alone (M) %, is close to statistical significance at p value = 0.060, but not below our threshold.
We will discuss the importance of p values in determining analysis more in the results section.
To determine the best gamma value for our SVC model, we utlized cross validation scores. We tested gamma values within the range of \({6^{-4}}\) to \({6^{4}}\). Our experiment showed that the best gamma value was 0.027777, which resulted in a training accuracy of 93.6% and a testing accuracy of 90.5%. This testing accuracy is above our base rate by 4%.
Cross validation was used to determine the optimal maximum depth for the decision tree model. The optimal maximum depth was 5, the training accuracy was 93.4% and the testing accuracy was 90.07%. This testing accuracy was higher than our base rate.
We then plotted some choropleth maps to compare our predicted data to the actual data. We utilized the GeoPandas package in python in order to map our data. We utilized this dataset, United States Map of Counties, to combine a map of the United States counties with racial/income demographics as well as AQI numbers.
One of our first results had little to do with modeling and more to do with visualizing the bias from features that would represent bias and showed some importance in our feature importance exploration. The first was household income, which represented the median household income from each county. The initial trend is below.
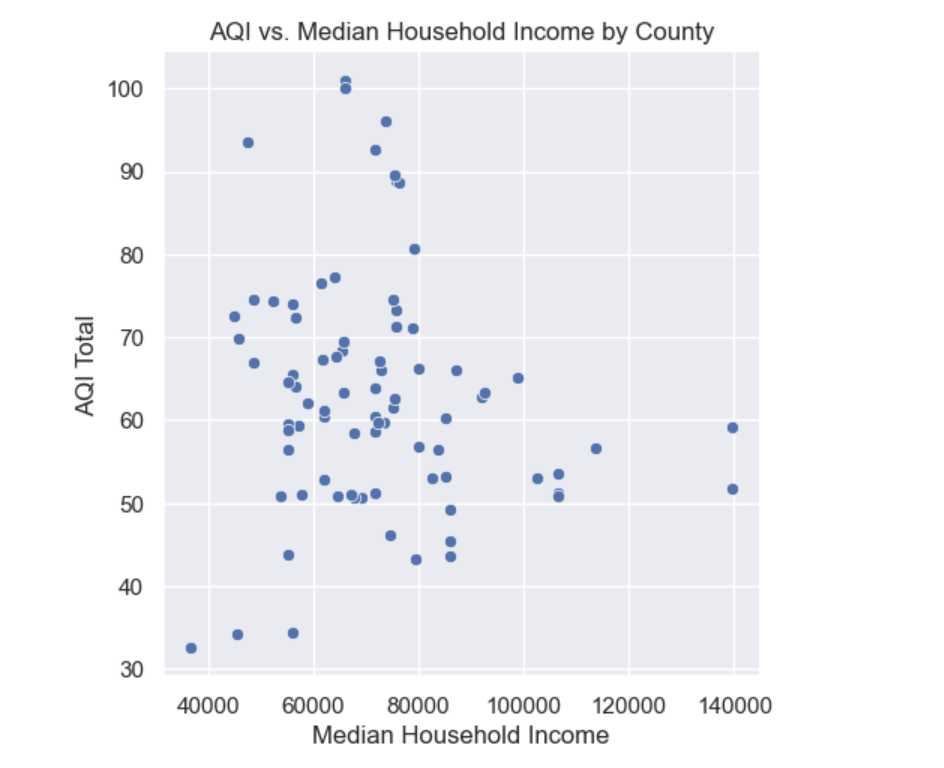
This image demonstrates an interesting trend; it is most definitely not linear, but there are clear trendlines. As median household income increases past 80,000 dollars, AQI levels above 70 are nonexistent. It is true that there is no clear ‘as median household income increases, AQI decreases by this amount’ linear relationship, but it is also clear that higher AQIs are associated with lower median household incomes.
The second feature that we wanted to explore was the total AQI vs. the percentage of white residents by county. What we found was fairly interesting – as the percentage of white residents increased, the AQI became less stabilized and included much higher AQIs. That trend can be observed below.
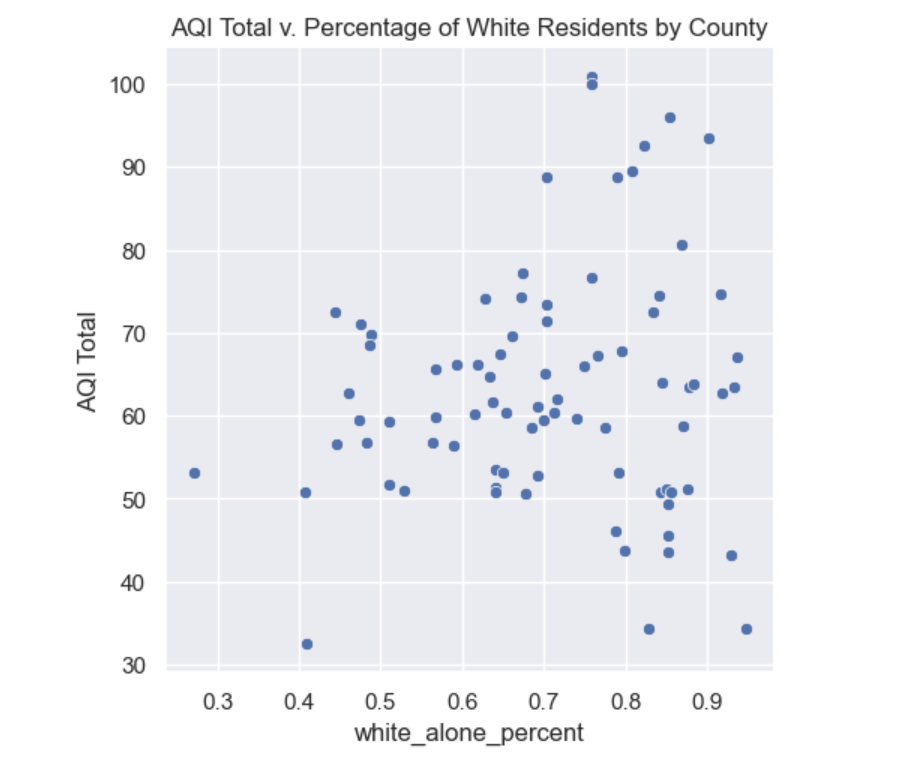
However, something else to note is that our sample size for higher percentages of white residents was much greater than the sample size for lower percentages of white residents. As percentage of white residents increases, the AQI range increases. However, higher percentages of white residents also increases the likelihood that AQI can be significantly lower (for the most part). With the exception of one remarkably low AQI at a county with ~40 percent white residents, the hlowest AQIs occur in counties with 80 percent or more white residents.
We decided to use our SVC model for further analysis. The overall accuracy of our model was 90.5%, but we also looked at the positive predictive value. That is the likelihood that a county predicted to have a low risk AQI actually has a low AQI. Our PPV was 91.1%.
We also looked into the overall FPR and FNR, which were 59.3% and 1.4%.
At the begining of the project, one of our goals was to investigate the bias of our model, so we decided to audit for income and racial bias.
We split our income data into two different counties: counties where the median household income was above $73,125 and those which were under.
The accuracy of our model for high income counties was 96.5%, while the accuracy for low income counties was 86.4%. This suggests that our model might have income bias. So, we tested for calibration. Calibration means that the fraction of predicted counties to have a AQI binary score of 1 (low risk) who actually had a score of 1 is the same across all income groups. So we will calculate this metric for both income groups. The proportion of high income counties predicted to have a low risk AQI is 0.50, but the proportion of low income counties predicted to have a low risk AQI was 0.39.
A model satisfies error rate balance if the false positive and false negative rates are equal across groups. Looking at the previously calculated FPR anf FNR, I would say that this model does not satisfy error rate balance. The FPR for high income counties is 50%, while the FPR for low income counties is 61.22%. The difference between the two rates is 10.1%. In general, the high FPR may stem from a lack of positive observation in the training data itself.
A model satisfies statistical parity if the proportion of counties classified as having a low risk AQI is the same for each group. So we compare the total number of predicted positives. The proportion of low income counties classifies as having a low risk AQI is 0.196, while the proportion of high income counties classified as having a low risk AQI is 0.058. This model does not satisfy statistical parity. The proportion of counties predicted to have a low risk AQI is not the same for low and high income areas. The is a 14% difference between the two groups.
We also decided to investigate the racial biases of the model. We split the data into two different categories. Counties where the majority of the population is white and those where there is not a majoroty white population. The accuracy for counties with a white majority population is 0.9122, but the accuracy for counties without a white majority population is 0.8511. The FPR for counties with a majority white population = 0.58; FNR for counties with a majority white population = 0.0123; FPR for counties without a majority white population = 0.6122; FNR for counties without a majority white population = 0.0199. Ideally a model would have the same vlaue for each metric across all groups, but this is not the case.
Next, we will look at calibration. The percentage of counties without a majority white population predicted have a low risk AQI who actually had a low risk AQI is 33.33%. The percentage of counties with a majority white population predicted have a low risk AQI who actually had a low risk AQI is 42.0%. This model is not calibrated as there is a 9% difference between the two groups.
A model satisfies error rate balance if the false positive and false negative rates are equal across groups. Looking at the previously calculated FPR anf FNR, I would say that this model does not satisfy error rate balance. The FPR for counties with a majority white population is 58%, while the FPR for counties without a majority white population is 61%.
A model satisifes statistical parity if the proportion of counties classified as having a low risk AQI is the same for each group. So we compare the total number of predicted positives. The proportion of counties with a majority white population classified as having a low risk AQI is 0.133 The proportion of counties without a majority white population classified as having a low risk AQI is 0.191. These values are more similiar in comparison to some of the other metrics investigated, but there is still a discrepancy between the two groups.
from geomapping import Mapping
import pandas as pd
from dataCleaning import DatasetClass
from sklearn.svm import SVC
from copy import deepcopy
ds = DatasetClass()
dataset = pd.read_csv("pollution_income_race.csv")
X_train, X_test, y_train, y_test = ds.train_test_data(dataset)
df = pd.read_csv("pollution_income_race.csv")
df = df.dropna()
mp = Mapping()
svc_model = SVC(gamma = .027777777777777776)
svc_model.fit(X_train, y_train)
test_combined = deepcopy(X_test)
test_combined["Predicted AQI Binary"] = svc_model.predict(X_test)
test_combined["Actual AQI Binary"] = y_test
#plotting predictions
mp.plot_df(test_combined, "Predicted AQI Binary")mp = Mapping()
mp.plot_df(test_combined,"Actual AQI Binary")The above mappings of the actual AQI binary and the predicted AQI binary using our SVC model demonstrates the high accuracy of our model, but also demonstrates the high numbers of positive samples we have in our dataset. One thing that we found when exploring the false positive and negative rates of our model was a disproportionately high false positive rate and a disproportionately low false negative rate. When determining how this occurred, we recognized that our dataset has many more ‘positive’ samples than ‘negative’ samples; in other words, we have a dataset that contains many more counties with ‘good’ air quality index than those with ‘bad’ air quality index. This is not something that is disheartening to learn, but rather carries a positive connotation. If most of the areas we are observing have an EPA-determined ‘good’ air quality index, it means that American urban counties are not all suffering from unhealthy air quality.
However, our model is still able to predict outcomes of ‘good’ or ‘bad’ air quality at a higher accuracy than the base rate. Going back to the statistical significance of our features, the most statistically significant features are the local date, the total population, and the total percentage of females. While this is not necessarily what we were expecting, it still provides interesting. Particularly when it comes to the demographic features, total population having a positive feature importance is very interesting. On one hand, more people utilizing vehicles, breathing out CO2, and otherwise creating pollutants is likely to increase the AQI and decrease air quality. On the other hand, people who are able to afford single-family homes and more room for their families are likely to live in areas with lower total populations. Both of these could help explain the importance of total population in determining air quality. If this project could extend into the future, an interesting project would be examining counties with good and bad air quality side by side and observing how their total populations and living conditions compare.
Overall, we found that racial/ethnic and income demographics hold some significance in determining air quality when using the AQI, but not necessarily in the way that we hypothesized. Perhaps use of a different metric of air pollution would change our outcomes; as seen in the introduction, many studies utilized PM2.5, or fine particulate air pollution, when testing racial/ethnic demographics effect on air pollution. These studies found much more statistical significance in how their features affect levels of PM2.5. In our model, the local date held much more significance than all racial and income demographics.
When we began this project, our main goals were to explore the relationships between income, racial demographics, and air pollution through the modelling process and hopefully gain insights into current inequalities surrounding pollution in the United States. We hoped that we would be able to implement and train a model to successfully complete binary predictions about ari quality based on the demographic data we selected from the United States Census.
In the end our model was able to predict air quality at a slightly higher rate than the base rate. One of the larger surprises of our project was that the statistical significance of median household income and racial demographics was somewhat low in predicting pollution. While it could be easy to lose perspective in the details of our project and feel disappointed in this result, when we take a step back and consider the implications for actual people in the United States this is a result we are happy with.
Additionally, we were quite successful in meeting the specific goals we defined at the beginning of this project. One of the challenges we initially identified that we were most worried about was the data cleaning process. While it did take a significant amount of time to gather the data we wanted to use, clean it, and combine data frames we were able to obtain training and test data with AQI, median income, and racial demographics by county. Our other initial goals included a working model that predicts whether a given county is a high pollution or low pollution area and a Jupyter Notebook with experimental graphics for both feature selection and our results. Both of these goals were met successfully and the feature selection process, which was something we thought might not happen if our plans did not go directly as planned, was an integral part of our project from which we gleaned many of the insights about our results.
As stated in both our introduction and the discussion of our results, there have been a number of studies that found Black Americans were more likely to live in heavily polluted areas and have health issues related to particle pollution. One hypothesis for why our results were less statistically significant than other similar work is that we were only considering urban pollution and that is not a comlete picture of life in the United States. There are many other historical legacies or redlining and discriminatory housing practices in suburbs that inform urban demographics, so if we had more time and access to data exploring rural areas would be an interesting extension of this project.
If we had more time we would also ideally consider features like poverty rates, unemployment rates, and income inequality in addition to median household income. Median household income is useful but there are many other things that contribute to the economic situation in a county beyond that and we would have loved to been able to compare how each were related to pollution rates. Finally, with more resources it would have been great to replicate our process considering PM2.5 instead of just AQI, the air quality index. The choice to use AQI was largely the result of what datasets were available to us but seeing how our model would perform in the context of a different measure of air pollution that has been shown to have racial disparities would be interesting and could potentially lead to an improved accuracy.
This project was largely broken down into the following stages: data selection and preparation, data exploration, feature selection, model selection, and experimentation/visualizations. Beyond that, the major tasks were creating our repository and writing this final blog post.
Kate selected our initial EPA data for the project proposal and defined the overall AQI based on multiple pollutants in the data set. Mia worked on finding census data that had racial demographics by county and Bridget found a data set that had income levels as well. The three of us then worked together on various facets of the data cleaning process.
Bridget took the lead on our feature selection process and consequently decided what features would be included/dropped for our model training. She additionally created visualizations for the experimentation surrounding feature selection. Kate then did some initial data exploration that found some loose patterns through plotting and mapping our selected features. She started the mapping source code using geopandas and Mia continued this process and improved the user experience by making our maps interactive. Then it was time to actually train and test our models. Kate did the initial experimentation with multiple models and compared the results to select the best one. There was some experimentation throughout that process and Bridget helped with the details of trouble shooting. Mia helped with the cross validation scoring implementation. Once we had a model, Kate was able to map our predictions using geopandas. Bridget and Mia worked on the statistical significance of our different features and interpretting the results. Mia also performed an income and race audit of our model based on the racial audit we performed earlier in the semester for a blog post.
When completing our project and writing the final blog post, Bridget authored our abstract, introduction, and values statement. Mia and Bridget both wrote parts of the results and methods section. Kate wrote the concluding discussion and parts of the experimentation and visualization section as well. We worked together to maintain our repository throughout the project.
I learned a lot from this process. I contributed to most parts of this project and was able to gain insight into all of the methods. The data cleaning method allowed me to practice combining multiple data sets. For most projects, the data will not be readily available or clean. Data cleaning is a great skill to have and will allow the fine tuning and tailoring of the data. I was also able to use some of my knowledge from the earlier portion of the class and apply it to this project.
I previously completed a blog post on classification models; I could use this knowledge for the implementation of different models using cross validation scores. I also learned to use the various Plotly features such as the geomapping choropleth functionality. This was a fun and important skill to learn, as we can know visualize our predictions and data. One of out other goals was to audit for different biases. We looked into the biases of income and racial demographics. I was able to practice some my statistical and analytical skills.
At the beginning of this project our goals were to compile a combined data set, a python package with our code and a final jupyter notebook. I believe that we have accomplished that. We have a combine dataset with racial demographic, income and EPA information. We also have crafted a jupyter notebook with all of our data cleaning, feature importance, classification modeling and bias auditing code. We also have this jupyter notebook with a more formal write-up of our process and results. The pieces of this project that I will carry forward are the collaboration aspects and the bias auditing. Now, I will think more critically about the biases, implications and dangers of future algorithms. The open communication and collaboration skills that I have improved throughout this process will also help me in my future endeavors.
I am surprised by how much I learned throughout the process beyond what I’ve learned in implementing blog posts and completing class warm-ups. A lot of the methodology required data cleaning and manipulating data sets, which is something I did not have a lot of experience with prior to the project. I also feel as though working in a team of three to delegate and complete different parts of the project was very valuable. It is easy to work in group projects and feel as though you did not complete enough, but with this project every aspect was equally as important and required the same amount of care. It also required very open communication with team members on what each of us were working on and pushing to GitHub.
I feel as though we achieved a lot, particularly in learning, throughout this project. We met our initial goals of exploring how racial and income demographics affect urban air pollution, particularily the AQI. Perhaps what we hypothesized wasn’t the outcome, but we were still able to explore how demographics affect the AQI. I feel as though our group also met the initial goals we put forth of meeting to discuss goals, meeting with Phil if we felt as though we were stuck, and communicating about what we were all doing throughout the project.
I am glad that I was able to work on a group project entirely directed by myself and my team before graduating college and moving into the workforce. I have worked on a few projects before, but working from raw datasets and creating my own datasets is not really something I have experimented with. I also feel as though working with three people is fairly unique; my other three large CS projects have been either in pairs or a much larger group. I feel as though it requires more thoughful delegation of tasks and understanding of one’s strengths and weaknesses. Overall I feel as though this project has taught me a lot about communicating with a team, working from brainstorm to implementation in a unique project, and how much work goes into machine learning projects prior to the actual model implementation,
Throughout this project, I feel that we met our process and final goals. We started with the intention to have a final Jupyter Notebook displaying our results and experiments, a python repository, and an audit. We succeeded in producing all of those deliverables and as a result I feel satisfied with the work we produced collectively. On a personal level, I set goals at the beginning of the semester to work on a project I was passionate about and that had something to do with environmental issues. Additionally, in my initial goal setting I stated that I wanted to focus on experimentation and social responsibility throughout the course and project process. I am really happy with how I was able to align my interests and goals with our project topic and as a result I was working on something I was interested in and passionate about.
I think I learned a lot through the data cleaning process and the experimentation aspects of the project. I was more familiar with implementation through other classes and working on a project that was so flexible and up to us helped me learn new skills and techniques for working with data that I think will be very useful moving forward into my career and life after Middlebury. Additionally, I think one skill I learned through this project was how to make decisions in the modelling process and more generally. Decision making is so fundamental to any aspect of machine learning, as we have seen throughout the semester, and being able to both make decisions without questioning myself and trust the decisions made by my teammates was a valuable skill I think I developed throughout this project.
As with any group project, I think working in a team for the latter half of the semester also improved my communication skills and let me learn my own strengths in the context of our project. I hope to carry both the concrete skills and the team work things I learned throughout this project beyond the course. I also think this project highlights that computing and machine learning projects are about real people and effect their lives, health outcomes, and more. That is a lesson from this class that I want to remain in the front of my mind as I move from an academic setting at Middlebury into the professional world.