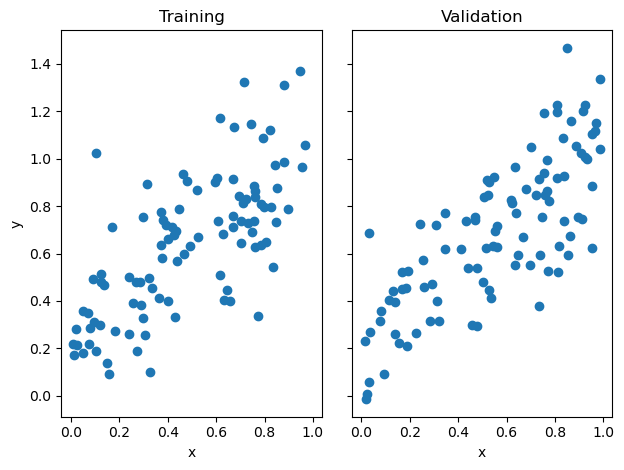
Linear regression is a model that helps find the linear equation that best explains the correlation between variables and an outcome. In this blog post, I implement linear regression in two ways.
The first is analytical, in which I use the formula: \[\hat w = argmin_{w}L(w) = argmin_{w}\lVert Xw - y \rVert^2\] This formula updates the weight according to the loss function: \[l(\hat y, y) = (\hat y - y)^2\] With this minimization equation, one can then take the gradient with respect to \(\hat w\), and solve for \(\hat w\) as \[\hat w = (X^TX)^{-1}X^Ty\]
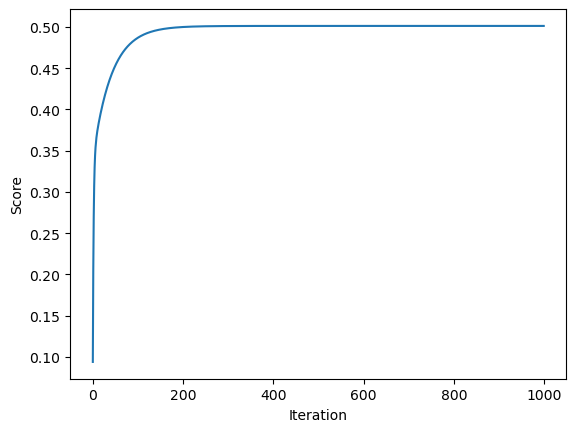
The second was with gradient descent, the formula for the gfradient being \[\nabla L = 2X^T(Xw - y)\] Each weight update, the gradient multiplied by an alpha value (default alpha = 0.001) was subtracted from the weight to obtain the new weight.
These two implementations of linear regression are seen below and my source code can be found at source code.
from linear_regression import LinearRegressionLR = LinearRegression()LR.fit_analytic(X_train, y_train) # I used the analytical formula as my default fit methodprint(f"Training score = {LR.score(X_train, y_train).round(4)}")print(f"Validation score = {LR.score(X_val, y_val).round(4)}")
Training score = 0.5013
Validation score = 0.6025
LR.w
array([0.75348988, 0.27263304])
Implementation Two: Gradient Descent Linear Regression
Observe the weight is the same as the analytical linear regression weight.
LR2 = LinearRegression()LR2.fit_gradient(X_train, y_train) # I used the analytical formula as my default fit methodLR2.w
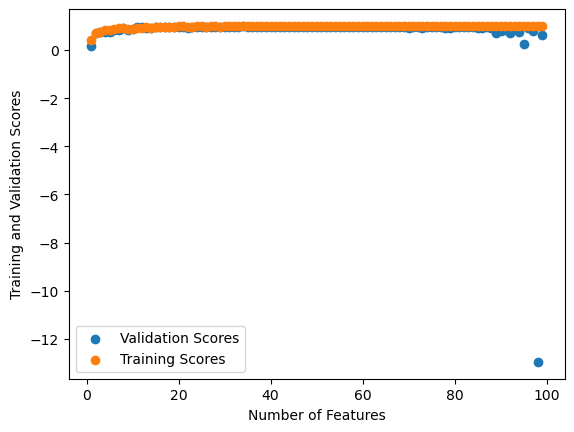
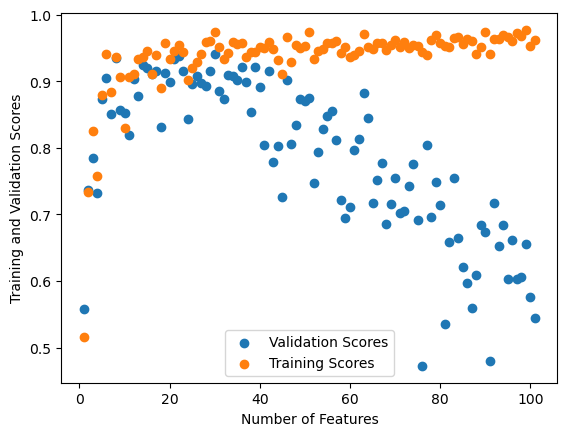
Below I ran an experiment; what would happen if I increased the number of features to right below the number of training data points? What occurred, shown very clearly in the graph, is overfitting. As I explain below, the validation score fell far below 0.0 with a significant increase in number of features.
The above observation of training and validation data demonstrates that increasing the number of features does not always help when it comes to validation data – the validation scores clearly fall off significantly as features expand, although not until the number of features near the value of n_train. This is a clear example of overfitting, when the training scores remain high (nearly 1.0), but the validation scores decrease below 0.0 (exemplary of a very bad model) when the number of features is almost equivalent to the number of data points. Full understanding of the training data does not translate to validation data, but rather handles only the specifics of the training data.
Lasso Regularization and Validation Scores: How Lasso Helps Protect from Overfitting
from sklearn.linear_model import LassoL = Lasso(alpha =0.001)
In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.
Lasso(alpha=0.001)
L.score(X_val, y_val)
0.6076240794781351
Lasso Validation Scores
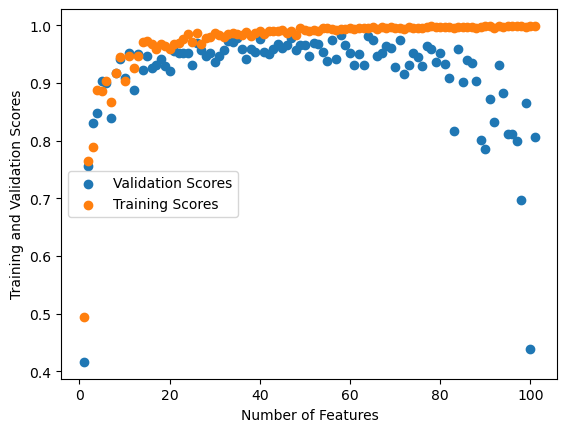
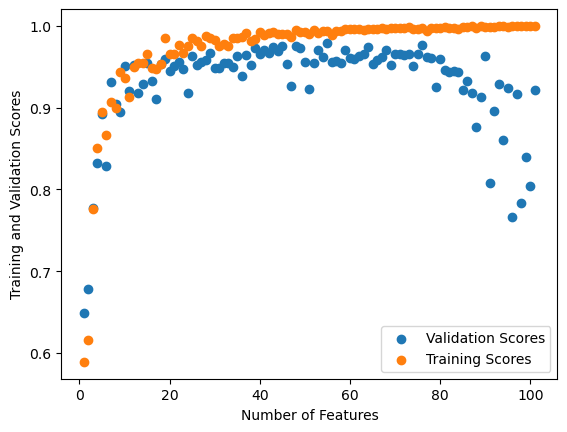
As seen below, I demonstrate three graphs which show the validation and training scores for LASSO regularized linear regression models with three different alpha values. In all three, the validation scores decrease, but not nearly with the same drastic change as with regular linear regression.
With LASSO regulation, when the number of features gets large the validation scores still drop. However, they remain higher than with normal linear regression. They still fall off significantly when number of feature increase, but they do not fall as far as the linear regression models did (i.e. on this specific data, LASSO falls to a little under 0.5 validation score whereas linear regression falls under 0.0 validation score). This demonstrates how LASSO regularization helps overparametized models – it helps protect the model (at least slightly) from overfitting.
Changing the alpha (i.e. making the alpha value 0.01 instead of 0.001) changes the validation scores even more significantly. The validation scores fall off much earlier – around p_features = 50 they start decreasing – but they still do not fall as low as the linear regression validation scores (they reach the same score as with alpha = 0.001).
/Users/bridgetulian/opt/anaconda3/envs/ml-0451/lib/python3.9/site-packages/sklearn/linear_model/_coordinate_descent.py:631: ConvergenceWarning: Objective did not converge. You might want to increase the number of iterations, check the scale of the features or consider increasing regularisation. Duality gap: 5.657e-02, tolerance: 4.368e-02
model = cd_fast.enet_coordinate_descent(
/Users/bridgetulian/opt/anaconda3/envs/ml-0451/lib/python3.9/site-packages/sklearn/linear_model/_coordinate_descent.py:631: ConvergenceWarning: Objective did not converge. You might want to increase the number of iterations, check the scale of the features or consider increasing regularisation. Duality gap: 4.456e-02, tolerance: 3.745e-02
model = cd_fast.enet_coordinate_descent(
/Users/bridgetulian/opt/anaconda3/envs/ml-0451/lib/python3.9/site-packages/sklearn/linear_model/_coordinate_descent.py:631: ConvergenceWarning: Objective did not converge. You might want to increase the number of iterations, check the scale of the features or consider increasing regularisation. Duality gap: 1.295e-01, tolerance: 4.979e-02
model = cd_fast.enet_coordinate_descent(
/Users/bridgetulian/opt/anaconda3/envs/ml-0451/lib/python3.9/site-packages/sklearn/linear_model/_coordinate_descent.py:631: ConvergenceWarning: Objective did not converge. You might want to increase the number of iterations, check the scale of the features or consider increasing regularisation. Duality gap: 6.573e-02, tolerance: 4.222e-02
model = cd_fast.enet_coordinate_descent(
<matplotlib.legend.Legend at 0x7f9b01b55a60>
On the other hand, decreasing the alpha from 0.001 to 0.0001 makes the validation scores decrease much slower and to a much lesser extent. In the above graph, the validation scores with Lasso regularization only fall to around 0.75. Decreasing the alpha, therefore, increases the validation scores.